- Forests Over Trees
- Posts
- Can news beat AI?
Can news beat AI?

When I was a kid, there was one responsibility I took extremely seriously.
It wasn’t making my bed… it wasn’t doing my homework… no, those were not things I cared about. What I cared about was tackling my brother.
When breaking up an epic wrestling match between me and my brother, my mom made an offhand comment that became my secret mission in life:
So naturally, I used to watch him in the front yard while we were playing, secretly hoping he might meander towards the street, so I could protect him (and practice my moves). Honestly, there were a few false alarms… you can’t be too careful!
This is just one example of what I call “older sibling energy”. The responsibilities and the mindset that come from being older, wiser, and more capable.
What has any of this got to do with tech?
Well, the New York Times is putting out some major “older sibling energy” right now – suing Microsoft and OpenAI for copyright infringement.
Let’s get caught up before we talk about what happens next.
Act 1 – Entering the fight
Before November 2022 when ChatGPT came out, media companies and platforms were pretty nonchalant about AI. GPT-3 sounded like a Star Wars character (maybe an R2D2 rival?), OpenAI was a relatively unknown entity, and authors patiently did press tours and podcast circuits to drive sales. These were good times. Simpler times.
Behind the scenes, OpenAI was training its models… on any data they could get their hands on – including internet archives, books, and Wikipedia.
Here’s a breakout of the sources of training data for GPT-3, from a 2020 Cornell paper:

In this case, Common Crawl is just the internet archive (very wide/messy data), WebText2 is Reddit data, Books1+2 are samples of books from the public domain, and Wikipedia is… Wikipedia!
When people finally got their hands on ChatGPT, it was chaos. People were tinkering, opining, and excitedly speculating all over the place. But a few folks were not so excited:
Authors/Creators – they sued in droves. First, individual authors, like Sarah Silverman in July 2023, sued OpenAI for ingesting books without permission to train their models (source). Then in September 2023, a group of authors (the Author’s Guild) sued OpenAI for copyright infringement. And this wasn’t just any group of authors, people – this was like the Justice League – a superhero collection of our favorite authors, including: David Baldacci, George R.R. Martin, Jodi Picoult, and John Grisham (source).Here's a quote from an Authors Guild suit around that time (extremely well-written, obviously):
"The success and profitability of OpenAI are predicated on mass copyright infringement without a word of permission from or a nickel of compensation to copyright owners." (source)

2. Reddit and Other Data-Rich Platforms – They aren’t happy either. they realized they had handed away valuable data for free and immediately started battening down the hatches. As I wrote about in “Making Data Great Again”, Reddit closed off their free API (pissing off moderators, and risking serious long-term damage to the site) so that other would-be-AI-trainers would have to pay for access to Reddit data. StackOverflow and Twitter did the same thing, trying to shut off the spigot of value gushing out of their platform as a result of letting OpenAI train on their data.
Act 2 – Older Sibling Energy
With ~$2.3B in annual revenue and over 10 million subscribers, the NYT has a much bigger stick than the others that have sued so far. They launched their own suit in December 2023 and published about it immediately. That’s one way to be the first to break a news story! Here’s what the suit alleges:
Millions of articles published by the NYT were used to train AI models that now compete with NYT as a source of reliable information
Billions of dollars in statutory and actual damages have been incurred
NYT believes it is among the largest sources of proprietary information for OpenAI and Microsoft’s products
Side note: I think it’s probably accurate to suggest that many articles have been used for training (1) and that there are some damages associated with that(2). But in my opinion, the third one is a tough sell. Unlike Reddit, which formed a distinct/important dataset, NYT was likely just included in the Common Crawl… one of billions of websites included. I don’t know how they are justifying that claim, but interested to learn more about this in the next few weeks…
So zooming-out, NYT is trying to claw-back the data value that has already leaked… But this action, and the actions of all the suing authors and platforms so far, probably isn’t the end game.
So what is the end game? Who wins the fight now that the older sibling is jumping in?
Act 3 – Winning The Fight

I don’t have a crystal ball, but I’m a glutton for prediction punishment… let’s give it a shot!
In the short term, it’s suit time. The suits will focus on past uses of data (particularly for training), and the outcomes will depend on who’s asking. For example:
I think the NYT will win the suit and OpenAI will pay a fine (and then be fine).
Other large media companies will follow the example set by the Times and sue as well, and some of them will win too.
Smaller companies probably won’t sue or won’t win. Why?
The same reason I’ve talked about ad nauseum (including in Revolving Door and FTC 101) – unfortunately, size matters in court battles.
In the medium term, the attention will shift away from training/one-time use, and more towards ongoing licensing, so you can get fresh, up-to-date news in your chat responses. CNN and Fox are apparently already in talks with OpenAI about this! For these ongoing licensing deals, there will be a prisoners’ dilemma that plays out among the authors guilds, publishers, and news outlets:
For the first large players in each group, cutting a deal with OpenAI could have HUGE monetary upside.
But for those that are slower to decide or commit, being the 10th news outlet to agree to a deal with them (or other AI companies) won’t bring the same negotiating leverage, resulting in lower prices on deals.
And that’s the dilemma – they would all be better off if nobody does a deal with OpenAI, but because there are rewards to be had if you do (and do it quickly), they will all try to do it. Doing deals will be bad… I think… for the long term.
In the long-term, with news data available in chat apps, traffic to news/media sites will go down. This will accelerate the trend of news/media consolidation and decline, and probably lead to more media bubbles too (only seeking out and reading things you agree with).
Anyway, that’s my opinion on what’s most likely to happen. But you know what would be more awesome?
A more awesome, positive alternative
If you’re the New York Times, why not build ChatNYT? Users could chat with you about the Fed’s latest moves, or ask you how your famous chocolate chip cookie recipe tastes so damned good, or complain about the Wordle word that day…
If (and this is a big if) you can eliminate hallucinations when it comes to chatting about news, ChatNYT sounds pretty cool to me.
They just hired an Editorial Director of AI Initiatives a few days before the suit dropped, so maybe they’re way ahead of me. In any case, should be interesting to see what happens next.
Bonus Bullets:
Quote of the Week
You’re crazy until you’re successful, then you are a genius.
– Jimmy Donaldson (Mr. Beast)
Quick News Reactions
Bitcoin ETFs approved – I’m not sure we are fully out-of-the woods yet economically, but don’t tell crypto that. Prices haven’t been this high since Q1 2022, and institutional investors have more access than ever, if they want it. Wild.
Fitbit founders leave Google – James Park and Eric Friedman are moving on. To me, this sounds like an earnout period has been successfully completed, because it’s almost exactly 3 years since the Fitbit deal closed for $2.1B. Nicely played!
SAP paying $200M+ to settle bribery charges – I always pictured SAP (maker of enterprise resource planning systems) as a boring, stuffy company. It’s weird to think of them in back rooms, lining people’s pockets. Not so boring after all!
X (aka Twitter) might be doing something smart – But don’t quote me on that. They announced deals with Jim Rome, Don Lemon, Tulsi Gabbard, and others to do shows that air first on X. This is the first genuinely interesting thing I’ve heard about X in months.
Overall Economy
This is the Weekly Economic Index published by the Dallas Fed. It’s made up of 10 different data sources from consumer to labor to production, and it’s designed to closely track US GDP. I’m going to keep an eye on it for at least a few months.
WEI reported last week — 2.4
Tech Equities & Bitcoin
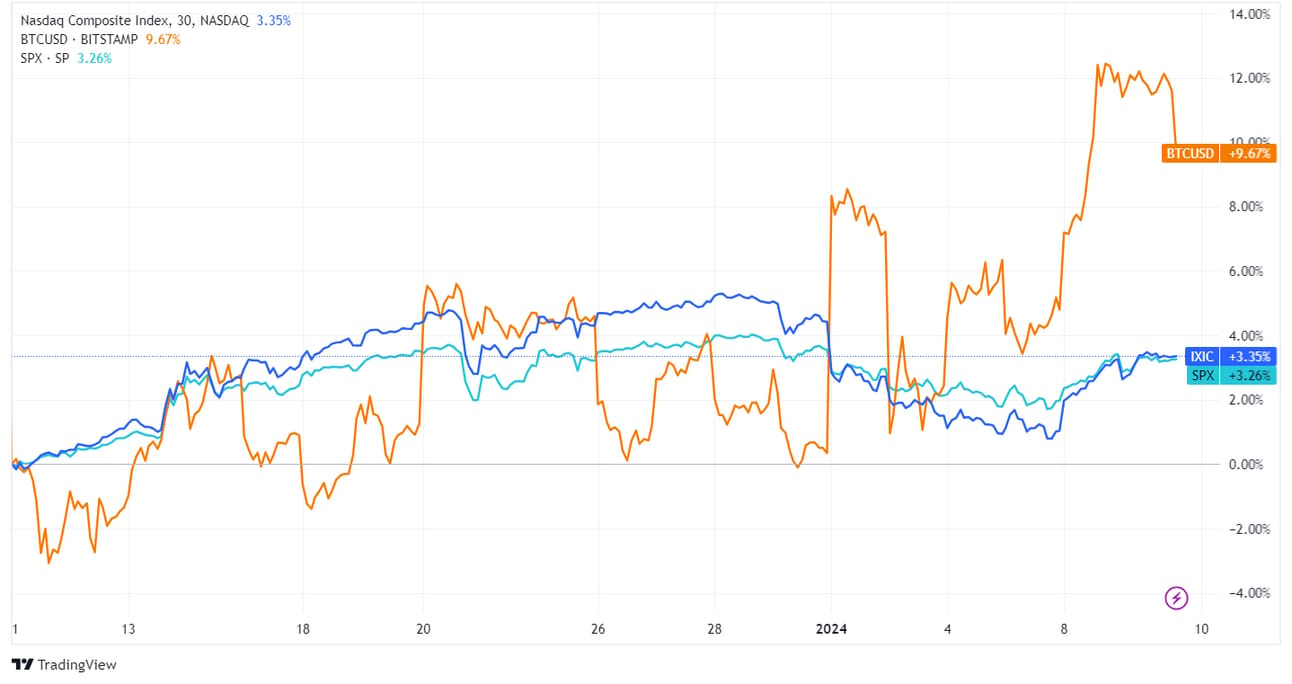
The Nasdaq (blue) closely tracks tech equities, and I added the S&P 500 (green) and Bitcoin (orange) for comparison.
Tech Jobs Update
Here are a few things I’m paying attention to this week:
Big Tech Job Posts: LinkedIn has 9,515 (+69.9% WoW) US-based jobs for a group of 20 large firms (the ones I typically write about — Google, Apple, Netflix, etc.).
Graph: Layoffs from 2022-2024 (Source: Layoffs.FYI). Note that this is showing in-progress numbers for the current month.